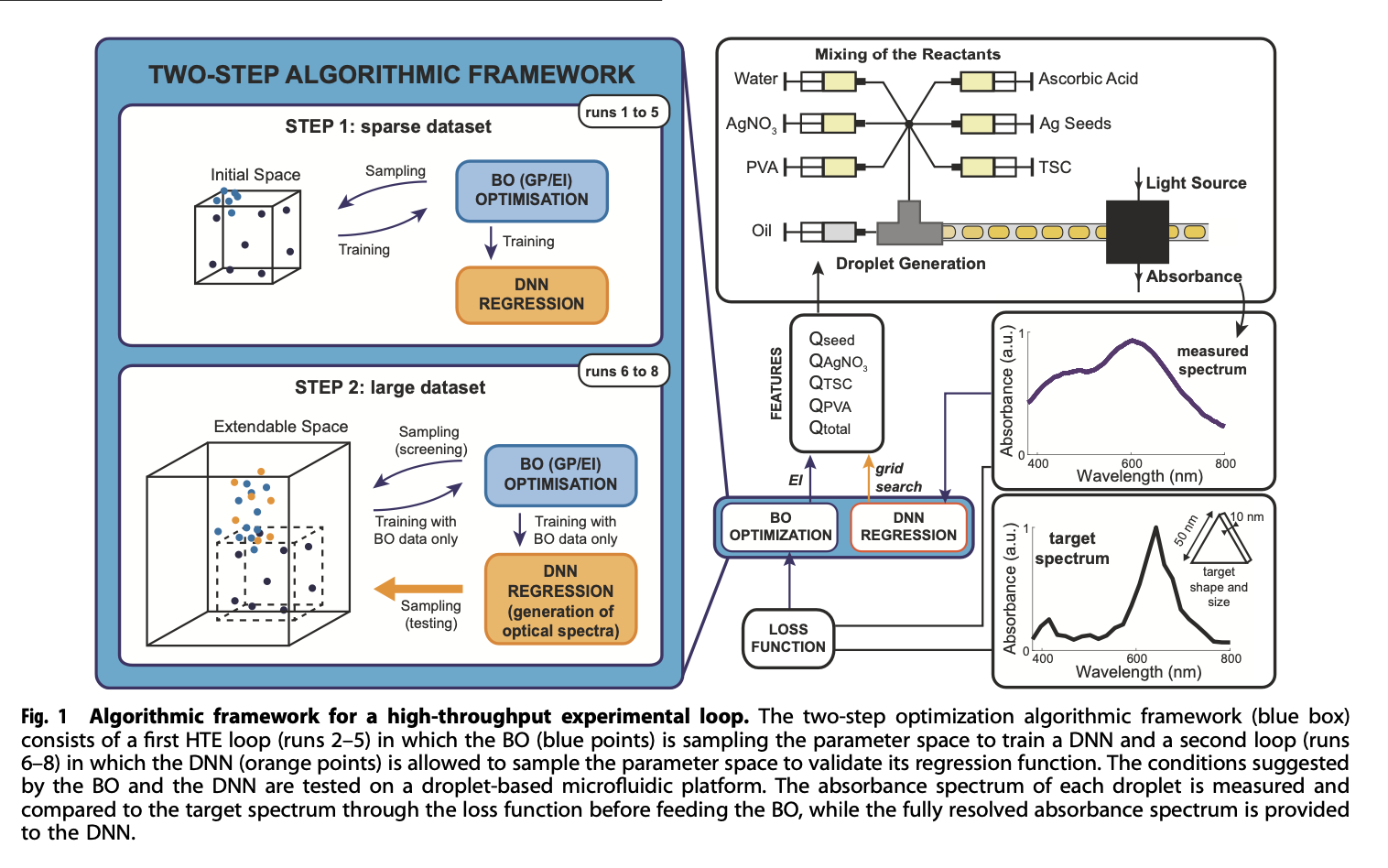
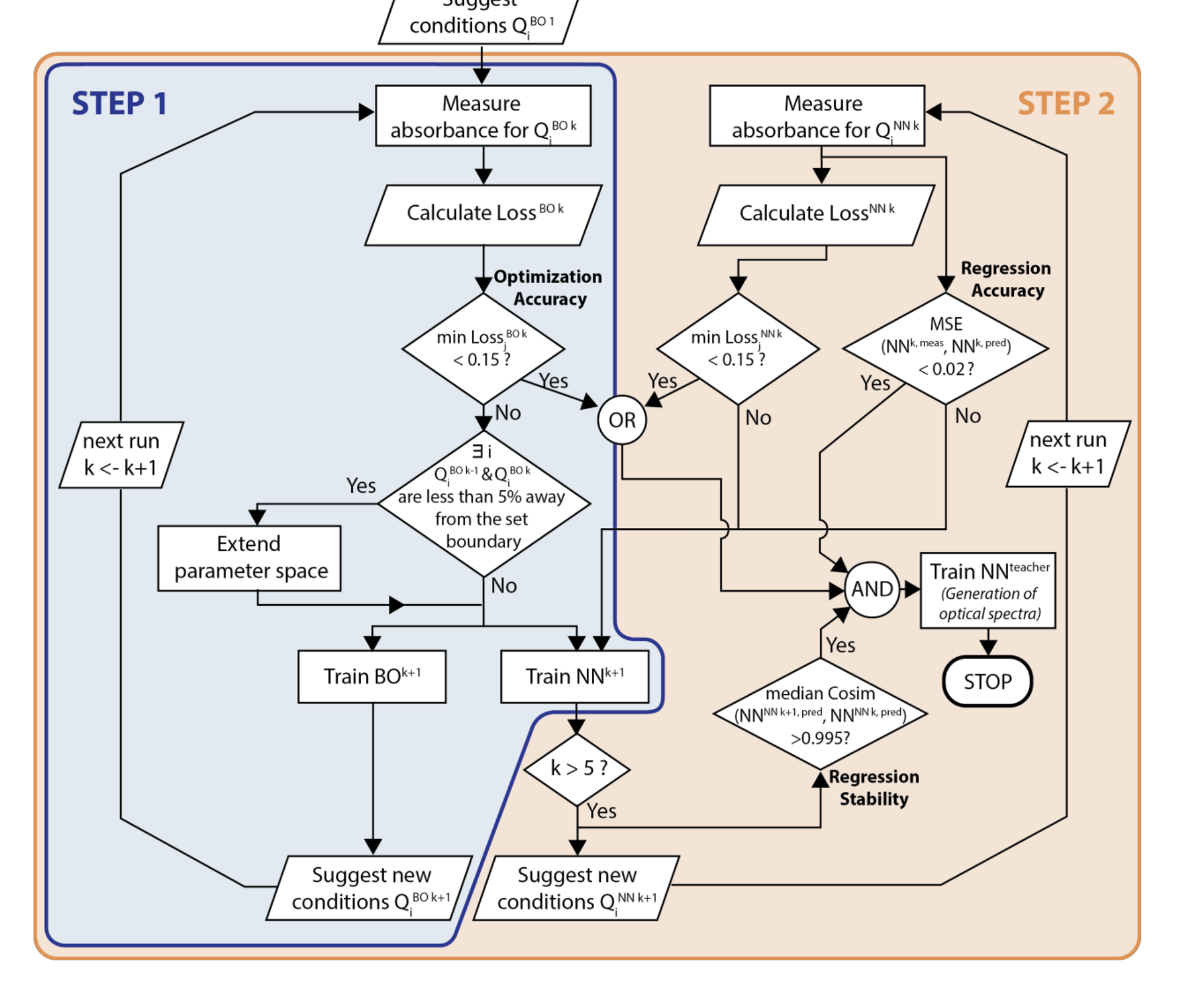
화학 실험 후 데이터를 축적하고 축적된 데이터를 통해서 ML 모델을 학습하고 다음 최적점을 찾기 위한 실험을 반복
Target loss function 은 관찰된 Spectrum 과 목표 Spectrum 사이의 Cosine Similarity 를 통해서 정의 ( = Wavelength 가 descrete 하기 때문에 각 Spectrum 의 강도를 통해서 Vector 로 표현하고 Cosine Similarity 를 통해서 측정한 유사도를 Target 으로 사용 )
STEP 1 에서는 Bayeskian Optimization(BO) 을 통해서 최적점을 찾기 위한 다음 실험 포인트를 찾고 실험하는 과정을 반복. Aquisition function 은 Expected Improvement 사용
일반적인 BO 방식을 통해 Expected Improvement 를 통해 다음 실험 포인트를 추천
데이터 포인트가 초기 설정한 Boundary 를 넘어가면 Boundary 를 조정해줌
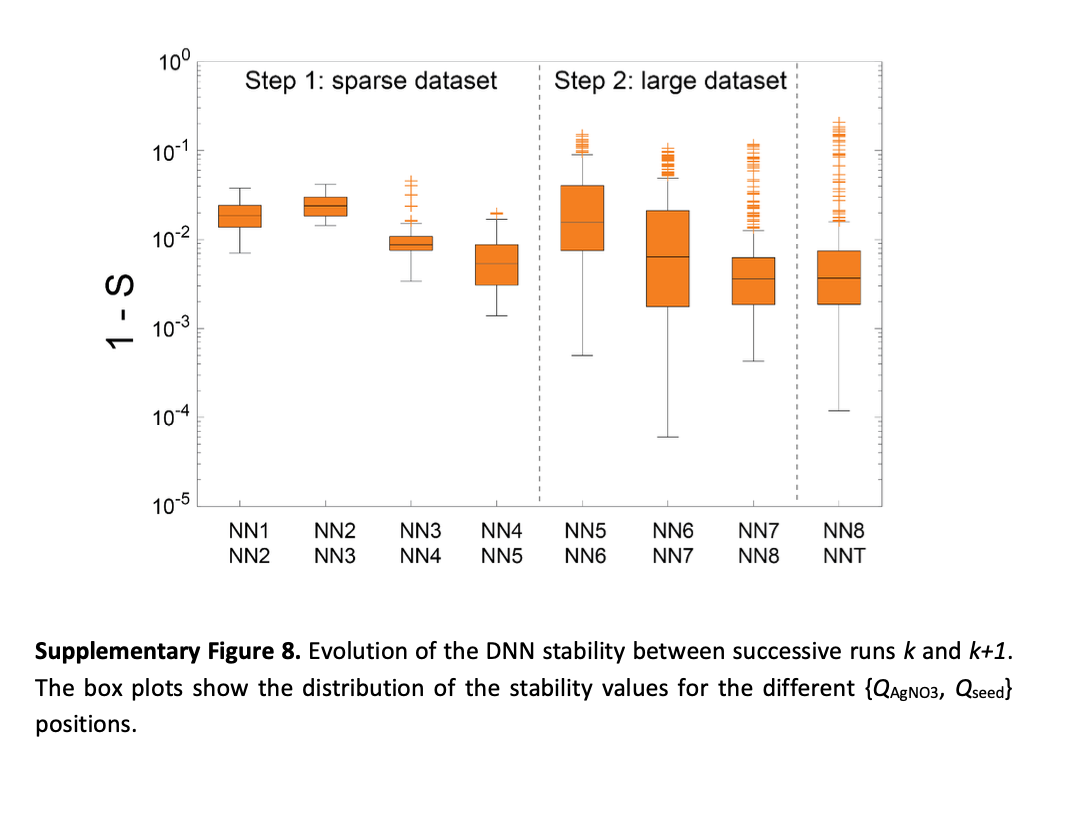
STEP 2 에서는 BO을 통해서 얻은 데이터 포인트를 통해서 DNN 모델을 학습시키고, DNN 모델을 통한 Next Point 추천과 BO 을 통한 Next Point 추천을 비교하여 두 방법론의 성능 비교
BO 의 surrogate model은 Input 에서 Loss 모델링하여, Loss 를 기반으로 다음 실험 포인트를 추천하고, DNN 의 경우는 Input 에서 Spectrum 을 예측하는 직접적인 모델링 후 DNN 이 예측한 Loss 가 가장 적을 것으로 추정되는 지점을 다음 실험 포인트로 추천
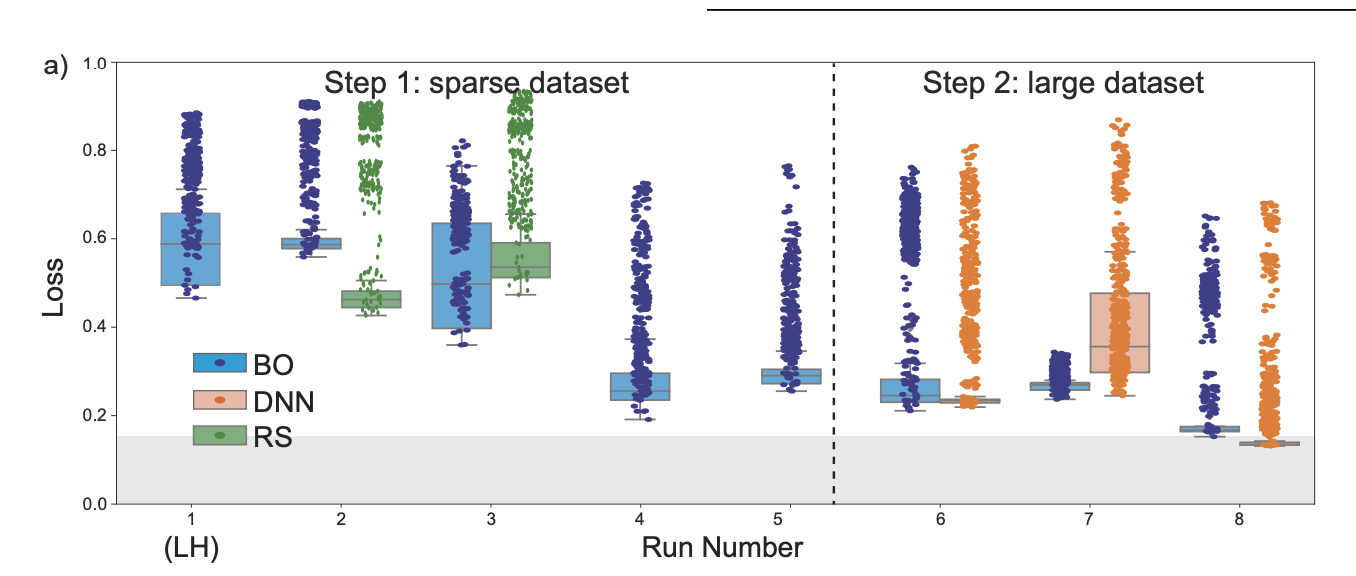
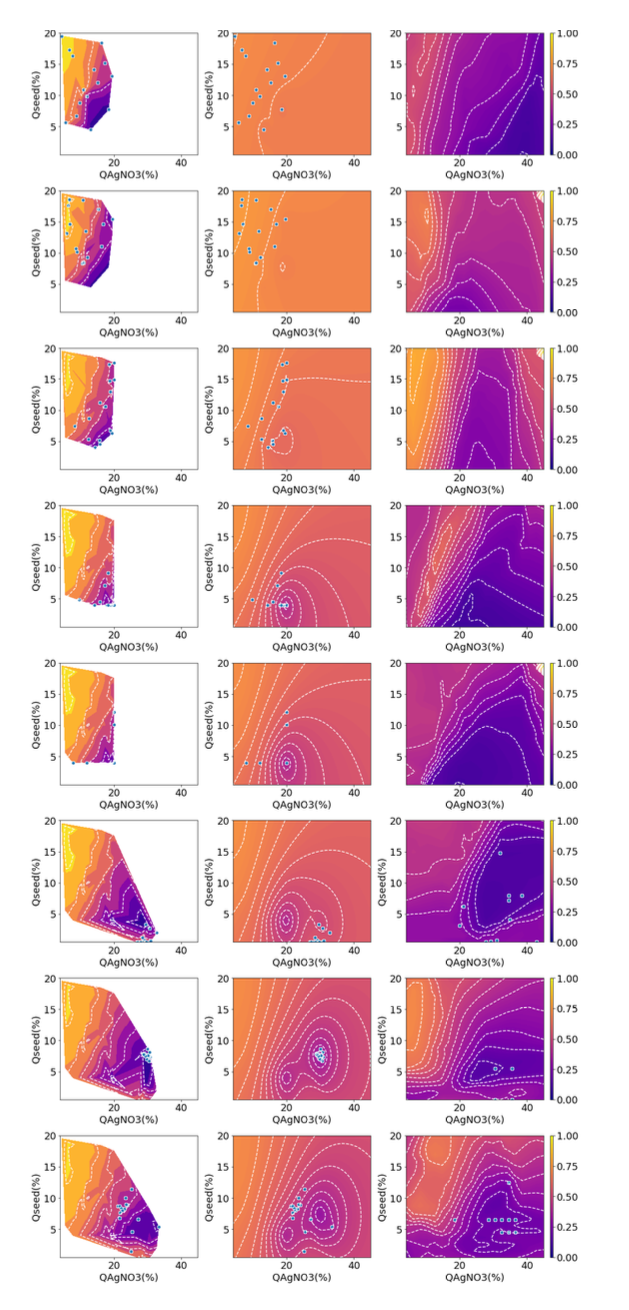
실험의 반복을 통해서 Round 8 에서 DNN 을 통한 Optimization 이 BO 보다 더 빠르게 목표 ( = 위 그림에서 아래 회색 영역 ) 에 도달함을 보여줌
Round 가 진행되면서 BO 를 통해 Sampling 한 실험 데이터가 Target Spectrum 에 가까워 지는 것 확인할 수 있었으며
DNN 의 예측 결과는 실제 실험 결과와 유사해지는 것 확인 할 수 있음
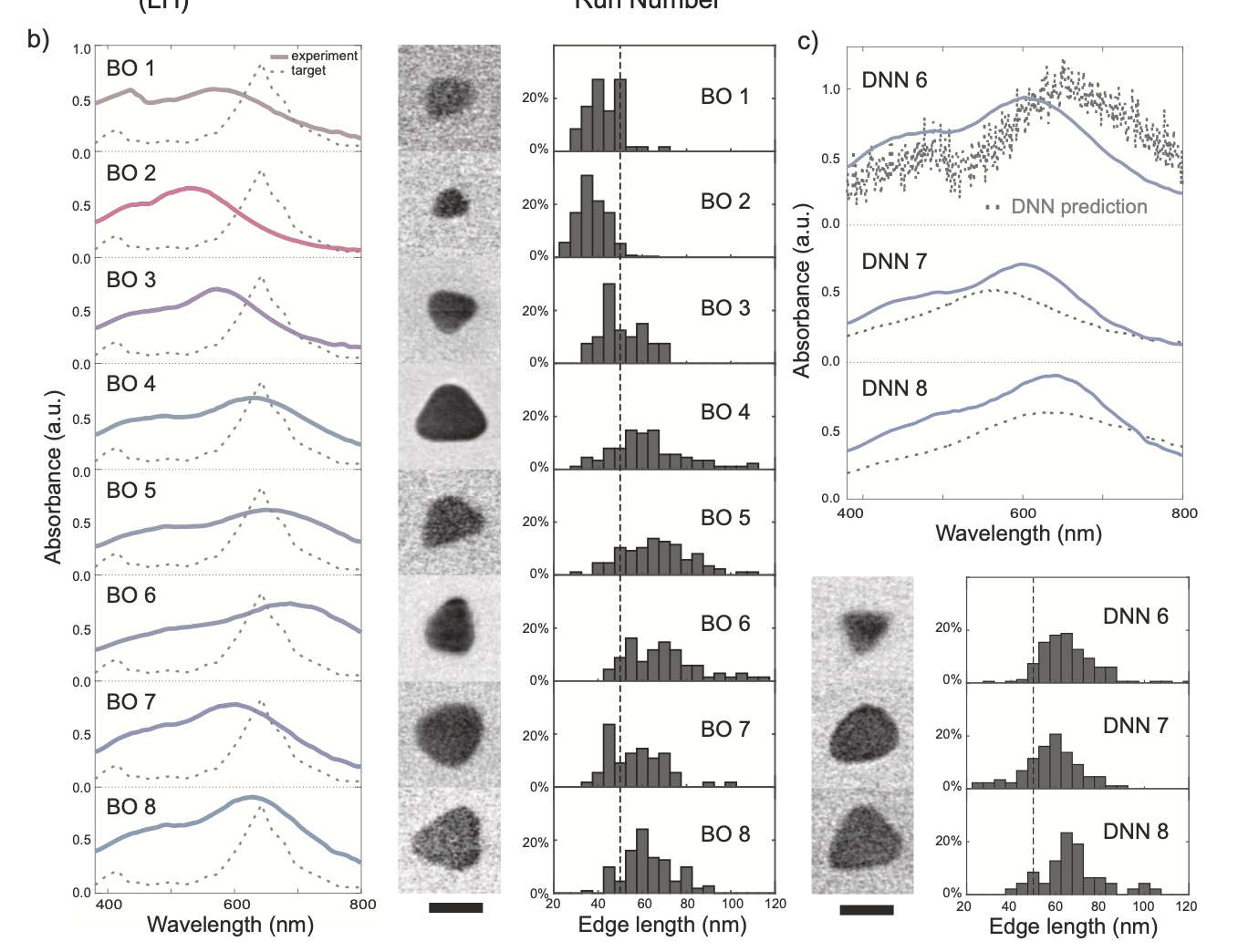
학습된 모델을 SHAP 이용해서 \((Q_{seed}, Q_{AgNO_3})\) 가 가장 중요한 변수임을 알아냈음
실험을 종료 후 DNN 과 BO 로 예측한 Loss 값을 \((Q_{seed}, Q_{AgNO_3})\) 에 대해서 그려보면 Fig3 와 같이 예측. 별 모양으로 예측한 부분이 최적점임
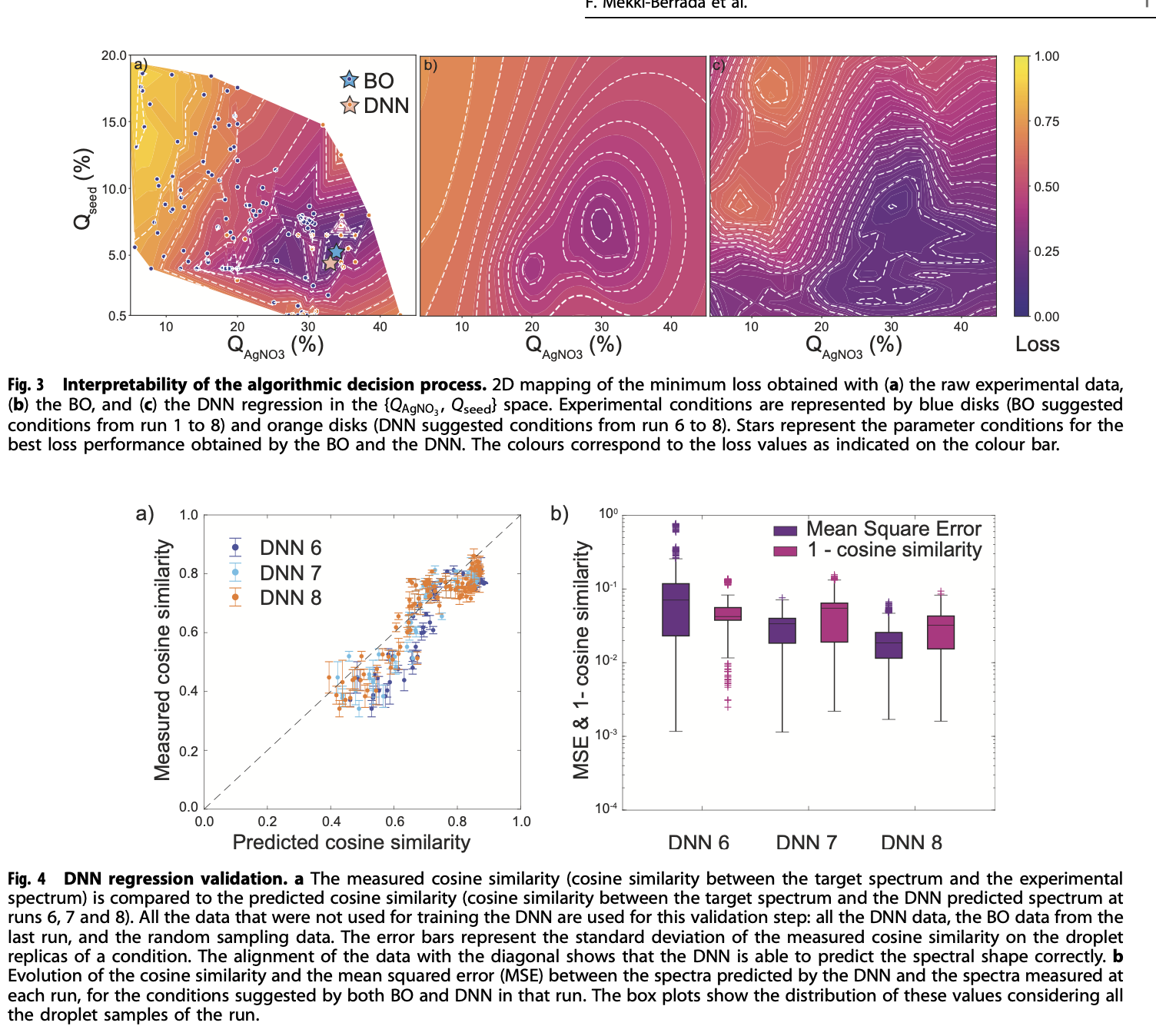
DNN 으로 예측한 결과가 실제 실험값과 얼마나 일치하는지를 Fig4 에서 확인할 수 있음. 새로운 포인트에 대한 예측력이 어느정도 유효함을 보여줌