pokemon
Training AI to Play Pokémon with Reinforcement Learning⚑
생각⚑
- Pokemon 의 예시를 통해 목적함수 설정에 따른 Agent 의 행위의 수렴 지점의 변화를 살펴볼 수 있었다.
- Grid World 의 예시를 통해 간단하게 목적 함수에 따른 Agent의 학습 과정을 생각해봤다.
- Agent는 단지 설계된 목적 함수에 맞춰 학습하고 행동한다.
- 특정한 환경에서 목적함수가 주저진 Agent / Envioronment 는 목적함수가 설계된 방식에 따라 수렴 지점이 결정된다.
- 목적 함수는 Agent의 행동을 결정하는 주요 요소이며, 경제학에서 말하는 유인과도 일맥상통한다.
- 현실 세계를 다양한 형태의 유인체계 ( Sexual / Monetary / Social ) 가 설계되어 있는 Agent 들의 집합이라고 생각할 수 있다.
- 이러한 관점에서 인간의 행동도 목적 함수에 따라 결정된다고 볼 수 있고, 이는 인간의 행동을 설명하는 한 가지 방법이 될 수 있다.
- 나는 이런 관점에서 사회를 해석하는 것을 좋아하고, 그래서 구조주의적 관점을 가지고 있다.
- 이런 관점에서 나는 리처드 도킨스의 Selfish Gene 을 좋아하고, 진화적 관점을 좋아한다.
Pokémon⚑
-
문제 1: 새로운 세상을 향해 나아가게 하는 방법
- Agent가 상하좌우로 움직일 때 배경 픽셀의 변화를 보상으로 정의하는 접근을 취했다.
- 이 방식은 탐색(Explore) 행동에 대한 보상을 정의하는 것이다.
- 목적 함수는 다음과 같이 정의되었다.
Object Reward Explore 1 
픽셀의 변화를 통해서 Explore 라는 보상을 정의하는 방식이 인상 깊다

일정한 시간이 지나면 Agent 는 각 위치에서 어떻게 움직일 것인지에 대한 정책을 학습한다
-
문제 2: 포켓몬의 성장
- 포켓몬 게임에서 단순한 탐색만으로는 충분하지 않다. 포켓몬을 수집하고 성장시켜야 다른 트레이너와 싸울 수 있다.
- 이를 반영하기 위해 목적 함수를 수정하였다.
Object Reward Explore 1 Levels 3 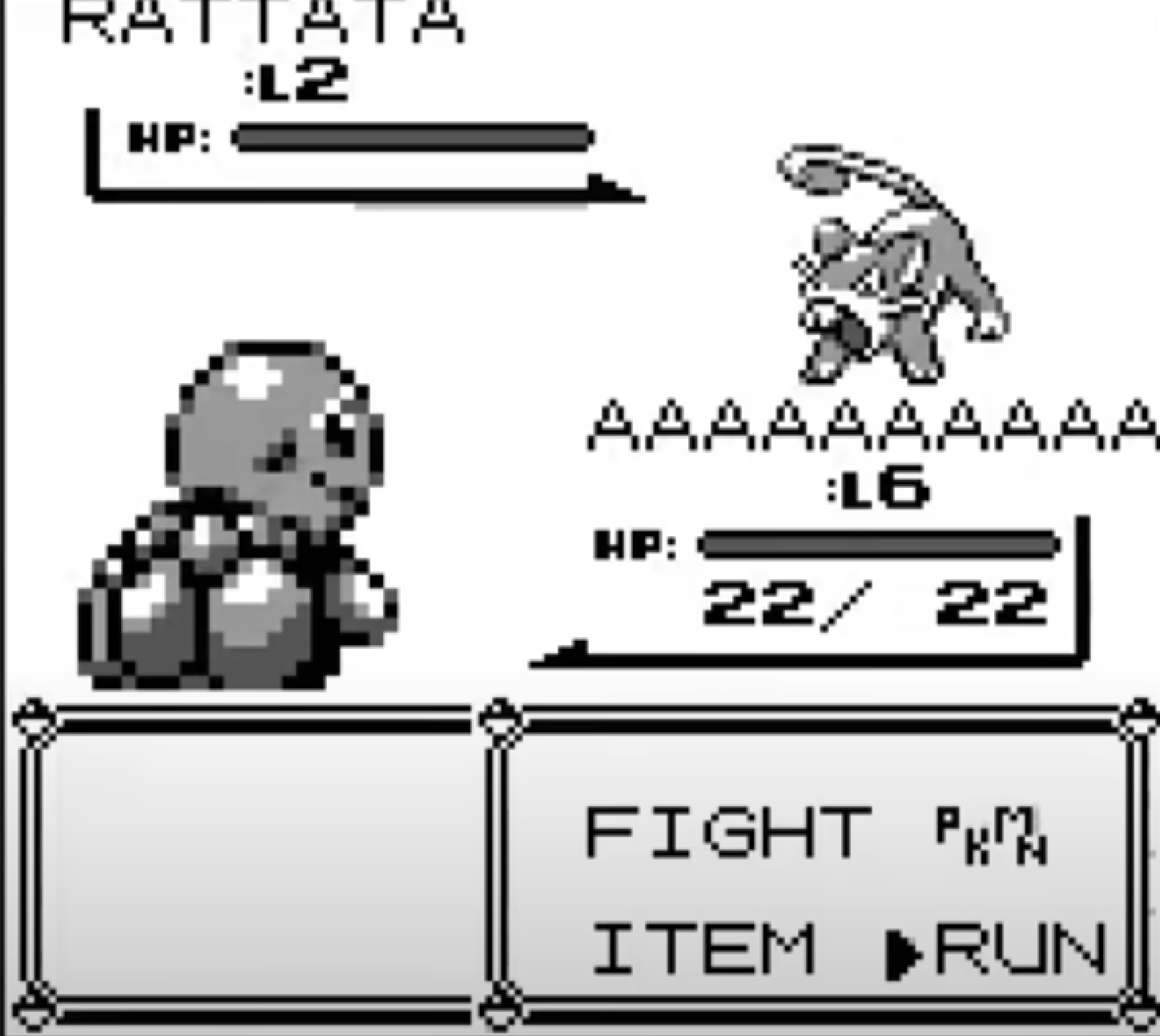
탐색만 하게되면 포켓몬을 만나면 도망을 가버린다
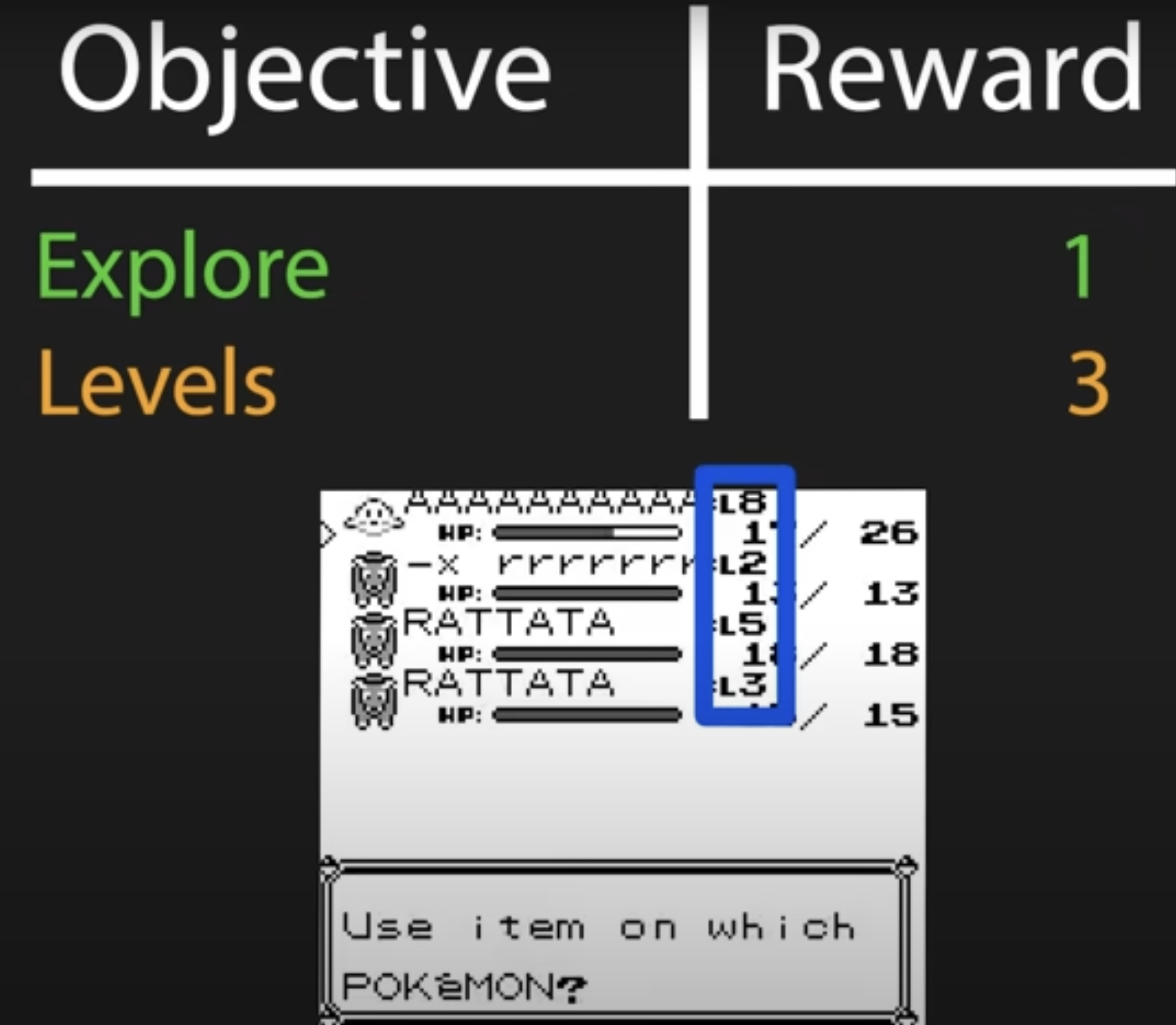
보유한 포켓몬의 레벨의 합을 이용해서 보상을 정의했다
-
문제 3: 포켓몬 센터의 트라우마(PC Trauma)
- Agent가 탐색과 레벨에 대한 보상 체계를 가지고 학습할 경우, 포켓몬 센터 근처로 가지 않게 된다. 이는 포켓몬 센터에 있는 PC에 포켓몬을 맡기면 레벨의 합이 급격히 떨어지기 때문이다.
- 레벨이 급격히 떨어지는 보상을 얻어버리면 Agent는 포켓몬 센터 근처를 피하게 된다. 이를 해결하기 위해, 0 이하의 레벨 변화는 무시하도록 목적 함수를 조정하였다.
| Object | Reward |
|---|---|
| Explore | 1 |
| Levels | Max(DEL Level, 0) |
<div style="text-align: center;">
<img src=/img/TSK-1825/5.png width=50%>
<p>포켓몬을 컴퓨터를 이용해서 맡기게 되면 엄청난 패널티를 받는다</p>
</div>
학습⚑
- 탐색, 즉 세상에 대한 탐색 과정에서 어떤 일이 벌어지고 있는지 살펴보자. 주인공이 움직이는 세계는 격자로 구성된 Grid World라고 부른다.
- 특정 위치에서 시작하여 목표 지점까지 가장 효과적으로 이동하는 문제를 고려해 보자. 예를 들어, 4x4 그리드 월드에서 Agent가 [0, 0]에서 시작하여 [3, 3]에 도달하는 것이 목표이다. Agent는 상하좌우로 움직일 수 있으며, 각 움직임에는 -1의 보상이 주어진다.
- Agent는 어떻게 학습하여 목표 지점에 도달할 수 있을까?
TD 알고리즘⚑
- \[ V(s) \leftarrow V(s) + \alpha [r + \gamma V(s') - V(s)] \]
- \( V(s) \): 현재 상태 \( s \)의 가치 추정 (현재 상태에서 목표까지의 기대 보상).
- \( \alpha \): 학습률 (0과 1 사이의 값으로, 새로운 정보가 기존 가치 추정에 얼마나 영향을 미칠지를 결정).
- \( r \): 현재 상태 \( s \)에서 취한 행동의 보상.
- \( \gamma \): 할인율 (미래 보상의 현재 가치에 대한 가중치).
- \( s' \): 다음 상태.
-
구성 요소의 역할
- 현재 상태 가치 \( V(s) \): 현재 상태에서의 가치 추정이다. 이 값은 업데이트를 통해 더 정확한 추정치로 개선된다.
- 보상 \( r \): 현재 상태에서 취한 행동의 즉각적인 보상이다. 예제에서는 목표 상태에 도달하면 1, 그 외에는 0이다.
- 다음 상태 가치 \( \gamma V(s') \): 다음 상태의 가치 추정치에 할인율 \( \gamma \)를 곱한 값이다. 이 값은 미래 보상이 현재 가치에 얼마나 영향을 미치는지를 나타낸다. 할인율이 1에 가까울수록 미래 보상이 현재 가치에 더 큰 영향을 미친다.
- TD 오차 \( r + \gamma V(s') - V(s) \): 현재 가치 추정 \( V(s) \)와 새롭게 관찰된 보상 및 다음 상태 가치 추정의 차이다. 이를 TD 오차(TD Error)라고 하며, 이 오차가 클수록 현재 가치 추정이 실제와 얼마나 차이가 나는지를 나타낸다.
- 학습률 \( \alpha \): 학습률은 새로운 정보가 기존 가치 추정에 얼마나 영향을 미칠지를 결정한다. 학습률이 높을수록 새로운 정보에 더 민감하게 반응하며, 학습률이 낮을수록 기존 정보에 더 무게를 둔다.
-
업데이트 공식의 의미
- 업데이트 공식은 현재 상태의 가치 추정 \( V(s) \)를 다음과 같이 갱신한다:
- \[ V(s) \leftarrow V(s) + \alpha [r + \gamma V(s') - V(s)] \]
코드 구현⚑
아래 코드는 일정한 확률로 무작위로 움직이는 Agent가 Grid World에서 목표 지점에 도달할 수 있도록 상태 가치 함수를 학습하는 예제이다.
import numpy as np
# Grid World 설정
grid_size = 4
gamma = 0.9 # 할인율
alpha = 0.1 # 학습률
num_episodes = 500
# 상태 가치 함수 초기화
V = np.zeros((grid_size, grid_size))
# 가능한 행동들: 상, 하, 좌, 우
actions = [(-1, 0), (1, 0), (0, -1), (0, 1)]
# 목표 상태
goal_state = (3, 3)
# 탐색 정책: epsilon-greedy
def epsilon_greedy_policy(state, epsilon=0.1):
if np.random.rand() < epsilon:
return actions[np.random.choice(len(actions))]
else:
values = []
for action in actions:
next_state = (state[0] + action[0], state[1] + action[1])
if 0 <= next_state[0] < grid_size and 0 <= next_state[1] < grid_size:
values.append(V[next_state])
else:
values.append(-np.inf) # 그리드 밖으로 나가지 않도록 함
best_action = actions[np.argmax(values)]
return best_action
# 에이전트 학습
for episode in range(num_episodes):
state = (0, 0)
while state != goal_state:
action = epsilon_greedy_policy(state)
next_state = (state[0] + action[0], state[1] + action[1])
if next_state == goal_state:
reward = 1
else:
reward = 0
# TD(0) 업데이트
V[state] = V[state] + alpha * (reward + gamma * V[next_state] - V[state])
state = next_state
# 학습된 상태 가치 함수 출력
print("학습된 상태 가치 함수:")
print(V)